Comment fonctionne le Retrieval Augmented Generation (RAG) ?
Le Retrieval Augmented Generation (RAG) est une technique qui combine les capacités de génération de texte des modèles de langage de grande taille (LLM) avec des techniques de récupération d'information, afin de mieux maîtriser le contenu des réponses produites par un LLM.
Le RAG est conçu pour surmonter les limitations des modèles de langage traditionnels (réponses incohérentes ou incorrectes lorsqu'ils ne disposent pas des informations nécessaires dans leurs données d'entraînement). Le RAG permet au modèle de langage d'accéder à des données externes en temps réel, dans le but d'améliorer la précision et la pertinence des réponses générées.
Le RAG se compose principalement de deux phases : la récupération d'information et la génération de texte.
1. Récupération d'information
La récupération d'informations
La première phase du RAG consiste à récupérer des documents ou des passages pertinents à partir d'une base de données ou d'un index de connaissances. Cette récupération est effectuée à l'aide de modèles de recherche sémantique basés sur des représentations vectorielles denses. Les techniques couramment utilisées incluent TF-IDF, BM25, et des modèles de récupération neuronale plus avancés comme les modèles de récupération dense.- Préparation des données : Les documents sont collectés et prétraités, incluant la tokenisation, le nettoyage des données et la gestion des informations personnelles (PII). Les documents sont ensuite segmentés en morceaux de longueur appropriée en fonction du modèle d'embedding choisi et de l'application LLM en aval.
- Indexation des données : Les embeddings des documents sont produits et un index de recherche vectorielle est hydraté avec ces données.
- Récupération des données : Les parties pertinentes des données sont récupérées en réponse à une requête utilisateur et fournies comme contexte dans le prompt utilisé pour le LLM.
2. Génération de texte
La deuxième phase consiste à utiliser les informations récupérées comme contexte pour générer des réponses. Un modèle de génération, tel que GPT, est utilisé pour créer des réponses textuelles basées sur le contexte fourni par la phase de récupération.- Architecture du modèle : Un modèle de génération est choisi ou conçu pour produire des réponses créatives. Ce modèle peut être un modèle de langage pré-entraîné comme GPT ou une architecture de génération neuronale personnalisée.
- Intégration : Les modèles de récupération et de génération sont combinés, le modèle de génération utilisant les informations récupérées comme contexte pour produire des réponses.
Avantages du RAG
Le RAG offre plusieurs avantages par rapport aux modèles de génération de texte traditionnels :- Précision et pertinence accrues : En intégrant des informations récupérées en temps réel, le RAG produit des réponses plus précises et contextuellement pertinentes.
- Transparence et traçabilité : Les modèles RAG peuvent fournir des liens vers les sources des informations utilisées, permettant aux utilisateurs de vérifier l'exactitude des réponses.
- Personnalisation : Les réponses peuvent être personnalisées en fonction des préférences de l'utilisateur, des interactions passées et des données historiques.
- Efficacité : L'automatisation des processus de récupération d'information réduit le temps et les efforts nécessaires pour trouver des informations pertinentes.
Applications pratiques du RAG
Le RAG trouve des applications dans divers domaines, améliorant l'efficacité et la précision des systèmes d'IA.1. Systèmes de questions-réponses avancés
Les modèles RAG peuvent alimenter des systèmes de questions-réponses qui récupèrent et génèrent des réponses précises, améliorant l'accessibilité de l'information pour les individus et les organisations. Par exemple, une organisation de santé peut utiliser des modèles RAG pour répondre à des questions médicales en récupérant des informations de la littérature médicale.2. Création et résumé de contenu
Les modèles RAG facilitent la création de contenu en récupérant des informations pertinentes à partir de diverses sources, permettant le développement d'articles, de rapports et de résumés de haute qualité. Ils sont également efficaces pour les tâches de résumé de texte, extrayant des informations pertinentes pour produire des résumés concis.3. Agents conversationnels et chatbots
Les modèles RAG améliorent les agents conversationnels en leur permettant de récupérer des informations contextuellement pertinentes à partir de sources externes. Cette capacité garantit que les chatbots de service client et les assistants virtuels fournissent des réponses précises et informatives lors des interactions.4. Recherche d'information
Les modèles RAG améliorent les systèmes de recherche d'information en améliorant la pertinence et la précision des résultats de recherche. En combinant des méthodes basées sur la récupération avec des capacités génératives, les modèles RAG permettent aux moteurs de recherche de récupérer des documents ou des pages web basés sur des requêtes utilisateur et de générer des extraits informatifs représentant efficacement le contenu.5. Outils et ressources éducatives
Les modèles RAG, intégrés dans des outils éducatifs, révolutionnent l'apprentissage en offrant des expériences personnalisées. Ils récupèrent et génèrent des explications, des questions et des matériaux d'étude adaptés, améliorant le parcours éducatif en répondant aux besoins individuels.6. Recherche et analyse juridiques
Les modèles RAG simplifient les processus de recherche juridique en récupérant des informations juridiques pertinentes et en aidant les professionnels du droit à rédiger des documents, analyser des cas et formuler des arguments avec une plus grande efficacité et précision.7. Systèmes de recommandation de contenu
Les modèles RAG alimentent des systèmes de recommandation de contenu avancés sur les plateformes numériques en comprenant les préférences des utilisateurs, en utilisant des capacités de récupération et en générant des recommandations personnalisées, améliorant l'expérience utilisateur et l'engagement avec le contenu.Défis et limitations des RAGs
Malgré ses nombreux avantages, le RAG présente également des défis et des limitations :- Ressources nécessaires : La mise en œuvre du RAG nécessite des ressources substantielles, y compris des outils de pointe et du personnel qualifié.
- Surveillance continue : Une surveillance et un raffinement continus sont nécessaires pour tirer pleinement parti des capacités du RAG.
- Complexité de l'intégration : L'intégration des modèles de récupération et de génération peut être complexe et nécessite une expertise technique.
Grands points fort des RAGs
En combinant des moteurs de recherche avancés dans la base de l’entreprise, avec les capacités génératives (de réponses en langage naturel) des LLM, les systèmes RAG peuvent synthétiser des informations à la fois contextuellement pertinentes, précises et à jour, ce que les LLM standards ne peuvent pas forcément faire.
Par ailleurs, les systèmes RAG peuvent exploiter toutes les informations non structurées de l’entreprise qu’ils peuvent indexées et rendre disponibles via de simples prompts.
Enfin, ils permettent de réduire le temps de développement car, notamment, ils ne nécessitent pas de création de graphes de connaissances (Knowledge graph) ou de curation et supposent un travail de nettoyage des données limité.
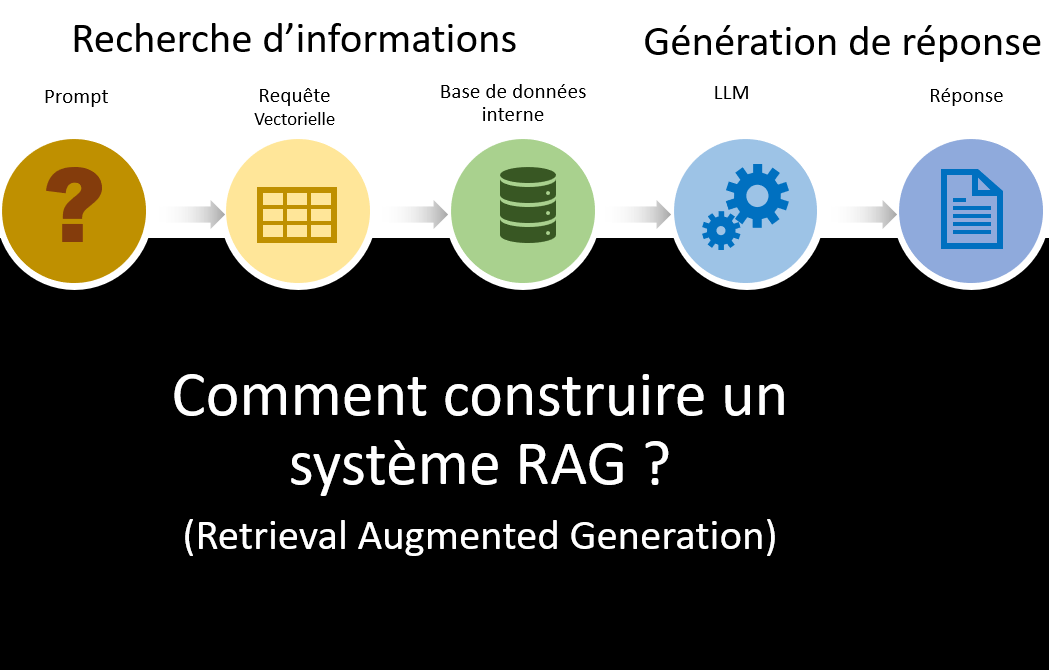
Pour fonctionner, un système de RAG se compose de deux briques
- Un composant de récupération qui effectue la récupération d'informations pertinentes pour une requête utilisateur à partir d'un magasin de données.
- Un composant de génération utilise les informations récupérées comme contexte pour générer une réponse à la requête utilisateur.
Si la création d’un système de RAG, ne nécessite pas un lourd travail de création de graph de connaissance ou de structuration des données, les développeurs doivent, néanmoins par des étapes :
- de prétraitement des connaissances spécifique à l’entreprise,
- de stockage les informations traitées dans un data store (base de données vectorielle),
- du choix de la bonne stratégie de sélection des artefacts (c’est-à-dire des éléments extraits de la base de données de l’entreprise qui contiennent des informations qui permettront au LLM de répondre correctement),
- de classement des artefacts correspondants
- d’appel à l'API du LLM en passant les requêtes des utilisateurs et les documents de contexte (les artefacts issus de la base de données de l’entreprise).
Voici une représentation de la façon dont on requête (Query Process) un système de RAG et de l’indexation (Index Process) des données lors de la phase de paramétrage du système.
Processus d'Indexation
Lorsqu’un utilisateur adresse une requête à un système de RAG, sa requête est transformée en un vecteur mathématique, c’est-à-dire une représentation sémantique (sens de la requête).
Ensuite, ce vecteur mathématique est comparé aux vecteurs mathématiques des données présentes dans la base de données, pour extraire les documents pertinents de cette dernière.
Ce vecteur mathématique est, en quelques sortes, une forme avancée de recherche par mot-clé, qui va pouvoir permettre d’extraire des documents en relation avec la requête, même s’ils ne contiennent pas les mots-clés de la requête.
Mais, pour cela, il faut qu’en amont, au moment de la construction du système, on ait créé la base de vecteur correspondant aux informations présentes dans la base de données.
Dans un système RAG, donc, le système de récupération fonctionne en utilisant des représentations vectorielles correspondant à une représentation sémantique compressée du document. Une représentation vectorielle est exprimée sous forme de vecteur de nombres. Pendant le processus d'indexation, chaque document est divisé en petits morceaux (chunks, en anglais) qui sont convertis en une représentation vectorielle à l'aide d'un modèle d'encodage. Le chunk original et la représentation vectorielle sont ensuite indexés dans une base de données. Les développeurs ont un véritable travail d’arbitrage au moment de la conception pour déterminer les stratégies de découpages en « chunks » des contenus à indexer ainsi que que la meilleure taille des chunks. Si les chunks sont trop petits, certaines questions resteront sans réponse; si les chunks sont trop longs, les réponses génèreront du bruit.
Il faut définir des stratégies adaptées à chaque type de document (texte, audio, vidéo…) au niveau du découpage en chunk et du traitement de ces chunks. qui existent nécessitent des étapes de découpage et des process de traitement différents. Par exemple, le contenu vidéo nécessite un pipeline de transcription pour extraire l'audio et le convertir en texte avant de l'encoder. Le choix du mode de représentation vectorielle à utiliser est critique, car changer la stratégie de représentation nécessite de réindexer tous les morceaux. Il ne faut, donc, pas se tromper, et, ce dès le départ. Une représentation vectorielle doit être choisie en fonction de sa capacité à récupérer des réponses correctes de manière sémantique. Ce processus dépend de la taille des chunks, des types de questions attendues, de la structure du contenu et du domaine d'application.
Processus de Requête
Le processus de requête au moment où le prompt de l’utilisateur est transformé en réponse.
Il se déroule en temps réel. Une question exprimée en langage naturel est d'abord convertie en une requête générale. Pour « généraliser » la requête de départ, le recours à un grand modèle de langage est nécessaire, qui permet d'inclure un contexte supplémentaire tel que l'historique des discussions précédentes dans la nouvelle requête. La nouvelle requête est alors transformée en un vecteur pour localiser les documents pertinents de la base de données. Les documents similaires à ce vecteur, c’est-à-dire les plus pertinents sont récupérés en utilisant une méthode de similarité telle que la similarité cosinus. Note pour les spécialistes : les bases de données vectorielles recourent à des techniques telles que les index inversés pour réduire le temps de réponse). Les chunks dont les vecteurs sont proches de ceux de la requête vectorisée, c’est-à-dire sémantiquement proches de la requête sont alors extraits car ils sont susceptibles de contenir la réponse.
Les documents récupérés sont ensuite reclassés pour maximiser la probabilité que le chunk avec la réponse, soit classé en haut de la liste, que l’on peut assimiler à la 1ere place dans Google lors d’une recherche par mot-clé.
L'étape suivante est le module Consolidateur, responsable du traitement des morceaux. Cette étape est nécessaire pour surmonter les limitations des grands modèles de langage : 1) limite de tokens et 2) limite de taux (rate limit). Les API tels qu'OpenAI ont des limites strictes sur la quantité de texte que l’on peut inclure dans un prompt. Cela limite le nombre de chunks que l’on peut inclure dans le prompt pour en extraire une réponse et une stratégie de réduction est nécessaire pour enchaîner les prompts pour obtenir une réponse. Ces services en ligne limitent également le nombre de tokens à utiliser sur un laps de temps donné, dégradant la latence d'un système de RAG. Les développeurs doivent, donc, réaliser des arbritrages difficiles, lors de la conception d'un système RAG.






