Les LLMs Open source alternatifs à ChatGPT / GPT

Il existe des modèles de languages concurrents de ceux utilisés par le GPT et le ChatGPT d'OpenAI.
Bloom (via HuggingFace)
Bloom est un modèle Open source fruit du travail du collectif BigScience, composé de plusieurs centaines de chercheurs issus de 60 pays de mai 2021 à mai 2022. Ce modèle est entraîné pour effectuer les mêmes tâches que GPT dans 46 langues naturelles, y compris certaines langues régionales ou en danger, ainsi que 13 langages de programmation. Les ensembles de données utilisés (28 pétaflops) pour l'entraînement sont tous disponibles en open-source, tout comme le modèle entraîné via HuggingFace. Le modèle contient 175 milliards de paramètres, soit la même quantité que GPT-3
Il est disponible sous la licence BigScience RAIL License, qui interdit son utilisation pour des objectifs contraires à la loi ou considérés comme non-éthiques.
Le fait que ses données d'entrainement soit Open Source, constitue une forme de garantie contre les risques de plagiat, par exemple.
Le code de Bloom
Projet open source Big Science
Espace collaboratif Notion du projet BigScience
Matériel nécessaire
Bloom est optimisé pour tourner sur une infrastructure de traitement de 8 GPU comptant 80 Go chacun et est commercialisé en version cloud.
Il s'agit d'une configuration conséquente.
StableLM
Stability AI connu pour son modèle Open Source de génération d'image Stable Diffusion, a lancé en avril 2023, plusieurs modèles de LLM conversationnels qui seraient plus performant sur la génération de texte et de code que ChatGPT. Les deux premiers modèles sont un modèle avec 3 milliards et 7 milliards de paramètres (contre 175 milliards pour GPT) Ils sont disponibles sous licences Open Source CC-BY-SA
Le code de StableLM
La version de démo du modèle 7B (7 milliards de paramètres) sur HuggingFace
Open Chat Kit (via Hugging Face)
OpenChatKit utilise un modèle de chatbot Opensource de 20 milliards de paramètres entraîn sur 43 millions d'instructions. Il peut résumer, générer des tableaux, classer et dialoguer. Le système de modération destiné à refuser les requêtes inappropriées est encore de développement.
OpenChatKit est un projet open-source qui fournit une base pour créer des chatbots spécialisés et généraux. Il se compose de quatre éléments clés :
- un modèle de langage étendu adapté aux instructions,
- des recettes de personnalisation pour affiner le modèle,
- un système d'extraction extensible pour augmenter le modèle avec des informations mises à jour en direct,
- un modèle de modération pour filtrer les questions inappropriées ou hors du domaine.
Le code d'OpenChatKit
Matériel nécessaire
Inconnu
Llama (Facebook)
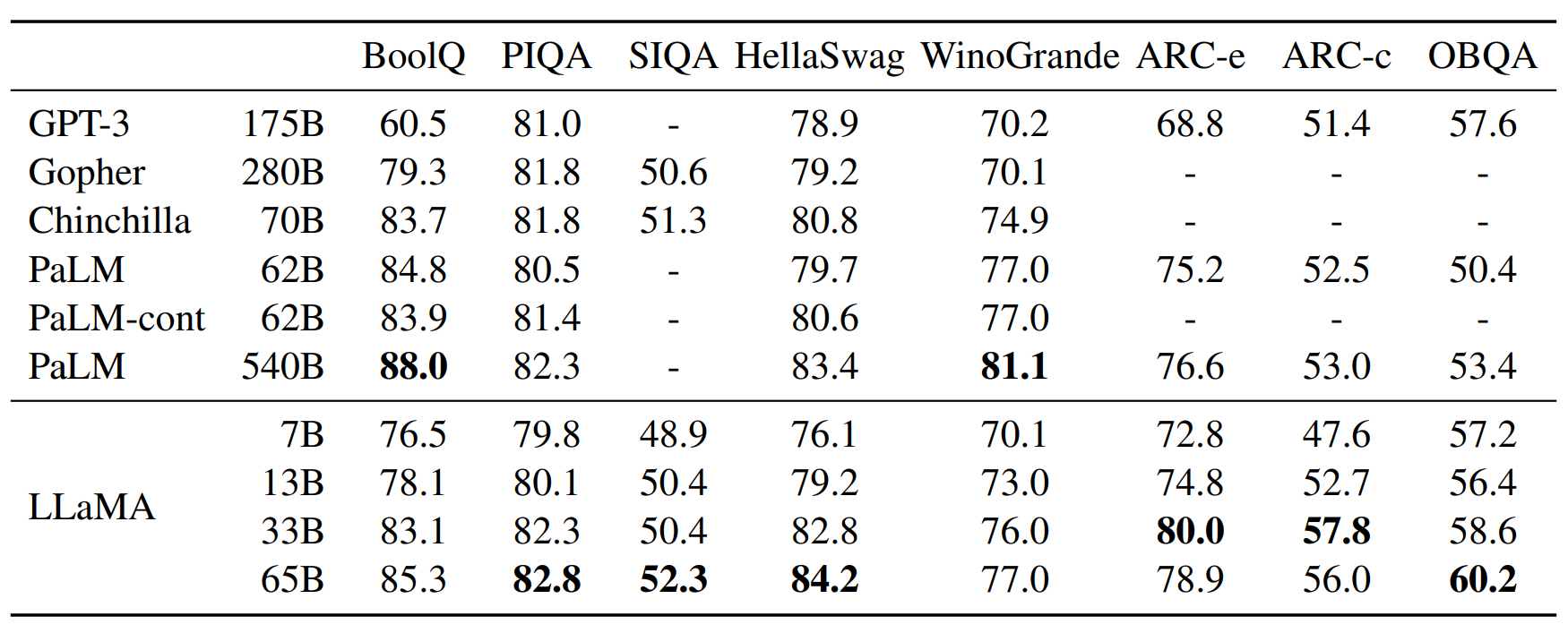
Meta a développé et publié, une série de quatre modèle de type LLMs sous le nom de LLaMA, sous une licence Open Source, explicitement destinée à la recherche et non à un usage commercial. Les universités, les organisations à but non lucratif et les laboratoires de R&D de l'industrie sont les seuls autorisés à avoir accès aux modèles LLaMA, à l'exception des concurrents de Meta. Le géant de la technologie affirme que le LLaMA-13B, en référence à ses 13 milliards de paramètres, dépasse le GPT-3 dans la plupart des KPI des benchmarks réalisés bien qu'il soit que le deuxième plus petit des modèles LLaMA et qu'il puisse fonctionner sur une simple GPU Nvidia Tesla V100, qui coûte quelques milliers d'euros. Le plus grand LLaMA, avec 65 milliards de paramètres, est censé rivaliser avec les modèles les plus sophistiqués de Google et de DeepMind (et battrait donc, le GPT3.5 d'OpenAI).
Entrainé sur 20 langues.
Benchmark
Le code de Llama
Présentation du modèle LLaMa sur Facebook
Demander un accès au code Llama
Matériel nécessaire
Inconnu
Alpaca (Standford)
Une équipe de chercheurs de Stanford a utilisé le plus petit des modèles Llama de Facebook pour créer un ChatGPT "light" qui enregistre des performances similaires. Pour ce faire, les chercheurs se sont appuyés sur le plus petit des LLM open source de Facebook, ont demandé au GPT d'OpenAI de générer 52000 questions/réponses et utilisé ces couples questions-réponses pour apprendre au modèle à répondre à des questions. Voici le détail de l'article de 24pm Academy consacré à Alpaca.
Le code d'Alpaca
Les 52 000 questions d'entraînement
Code pour générer les questions d'entrainement
Poids des paramètres d'Alpaca 7B
Code pour reproduire le modèle Alpaca
Page de Stanford sur le projet
Le model Alpaca expliqué en 10 mn (vidéo)
Matériel nécessaire
Inconnu
Vigogne (France)
Ce projet est une adaptation en mars 2023 du LLM Alpaca de Stanford qui a été ré-entrainé avec une traduction en français du jeu de données utilisé par l'équipe de Stanford.
Le code de Vigogne
Matériel nécessaire
Inconnu
OPT-175B (Meta/Facebook)
C'est un Large Language Model directement concurrent de GPT (175 milliards de paramètres), mais qui est Open Source. Mais il est sans interface conversationnelle. Sur un plan technique, il est comparable à GPT3, mais n'affiche pas nécessairement les mêmes performance du point de vue utilisateur.
Le code de d'OPT
La vidéo sur OPT: https://www.youtube.com/watch?v=Ejg0OunCi9U
►Zhang, Susan et al. “OPT: Open Pre-trained Transformer Language Models.” https://arxiv.org/abs/2205.01068
►Ma vidéo sur GPT-3: https://youtu.be/gDDnTZchKec
►Blogue de Meta: https://ai.facebook.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/
►Code: https://github.com/facebookresearch/metaseq https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
Matériel nécessaire
Inconnu
Blenderbot 3 (Meta)
C'est la version conversationnelle d'OPT-175B, c'est à dire un concurrent Open Source de ChatGPT
Le code source de Blenderbot
Site officiel (accessible uniquement à partir des US). Pour y accéder à partir de l'Europe, utiliser le navigateur Tor ou un VPN (voir le modus operandi sur cette page).
Présentation technique sommaire
Matériel nécessaire
Inconnu
GPT-J
GPT-J est un LLM open source développé par EleutherAI. GPT-J fonctionne de manière similaire au GPT-3 d'OpenAI sur diverses tâches de diffusion en aval sans prise de vue et peut même le surpasser sur les tâches de génération de code.
Le code de GPT-J
Accès à la version open source de GPT-J
Matériel nécessaire
Inconnu
Xgen7B
Xgen7B est un LLM open source développé par Salesforce et lancé fin juin 2023.
Entrainé sur 22 langues dont le français ( bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk, ja, zh)
GPT-J est un LLM open source développé par EleutherAI. GPT-J fonctionne de manière similaire au GPT-3 d'OpenAI sur diverses tâches de diffusion en aval sans prise de vue et peut même le surpasser sur les tâches de génération de code.
Selon les benchmarks internes de Salesforce, il obtient des résultats comparables aux meilleurs LLM OpenSource (juin 2023) sur des requêtes courtes.
En revanche, il obtiendrait de meilleurs résultats que les autres LLMs Open Source sur des séquences longues.
Plus d'infos
Annonce officielle de Salesforce
Le code de XGEN7B
Matériel nécessaire
Inconnu
Comparatif des grands LLM
Source: Devoteam et Journal du net
| Modèle | Licence | Fournisseur | Paramètres | Mode de machine learning | Cas d'usage |
|---|---|---|---|---|---|
| BERT / 2018 | Open source (licence Apache) | Google AI | Modèle de base : 100 millions, Modèle large : 335 millions. | Entraînement bidirectionnel ingérant le texte à droite et à gauche d'un mot pour déterminer son contexte. | Chatbots, analyse de sentiments, recherche d'informations, auto-autocomplétion, résumé. |
| Bloom / 2022 | Open source (BigScience RAIL License) | Projet BigScience / Hugging Face | 176 milliards | Modèle de langage autorégressif conçu pour générer des textes dans 46 langues et 13 langages applicatifs. | Génération de texte et de code applicatif. |
| CamemBERT / 2019 | Open source (licence MIT) | Facebook AI Research et Inria | Modèle de base : 100 millions | Modèle linguistique français basé sur BERT et RoBERTa et pré-entraîné sur le corpus multilingue Oscar. | Tâches de remplissage / masquage, soit masquer certains mots d'une phrase en vue de les prédire. |
| FlauBERT / 2019 | Open source (Creative Commons Attribution-NonCommercial 4.0) | CNRS | - Modèle de base : 137 millions, - Modèle large : 373 millions | BERT français formé à partir d'un corpus très large et hétérogène. | Classification de textes, paraphrase, inférence en langage naturel, analyse syntaxique, désambiguïsation. |
| GPT-3 / 2018 | Propriétaire (modèle distribué par Microsoft) | OpenAI | 175 milliards | Modèle génératif auto-supervisé, pré-entraîné sur un corpus anglais (il prédit le mot suivant pour générer des étiquettes). | Traduction, questions-réponses, composition de poésie, résolution de problèmes, génération de code, exécution de tâches avec raisonnement. |
| GPT-4 / 2023 | Propriétaire (modèle distribué par Microsoft) | OpenAI | Inconnu (centaines de milliards) | Modèle génératif auto-supervisé, Multimodal | Traduction, questions-réponses, composition de poésie, résolution de problèmes, génération de code, exécution de tâches avec raisonnement. |
| GPT-J / 2021 | Open source (Apache 2.0) | Eleuther AI | 6 milliards | Alternative open source à GPT-3. | Traduction, génération et complétion de code (avec de meilleures perf que GPT-3), chat, rédaction d'articles... |
| OPT / 2022 | Open source (OPT-175B License Agreement) | Meta | 175 milliards | Modèle de NLP génératif optimisé pour être entraîné sur une infrastructure 16 V100 GPUs de Nvidia. | Génération de texte, résolution de problèmes mathématiques, questions-réponses... |
| T5 / 2019 | Open source (license Apache) | 11 milliards | Modèle d'apprentissage par transfert, d'abord pré-entraîné sur une tâche globale avant d'être affiné sur une tâche plus spécifique. | Traduction automatique, synthèse de documents, questions-réponses, classification, analyse de sentiments. | |
| T-NLG et MT-NLG / 2020 | Propriétaire | Microsoft et Nvidia | - T-NLG : 17 milliards, - MT-NLG : 530 milliards. | Modèle de langage génératif. En lien avec Microsoft, Nvidia a présenté son successeur : le Megatron-Turing NLG. | Questions-réponses, résumé abstrait de plusieurs types de documents : e-mail, feuille de calcul... |






