Verba: The Golden RAGtriever, fonctionnalités et tutoriel pas à pas
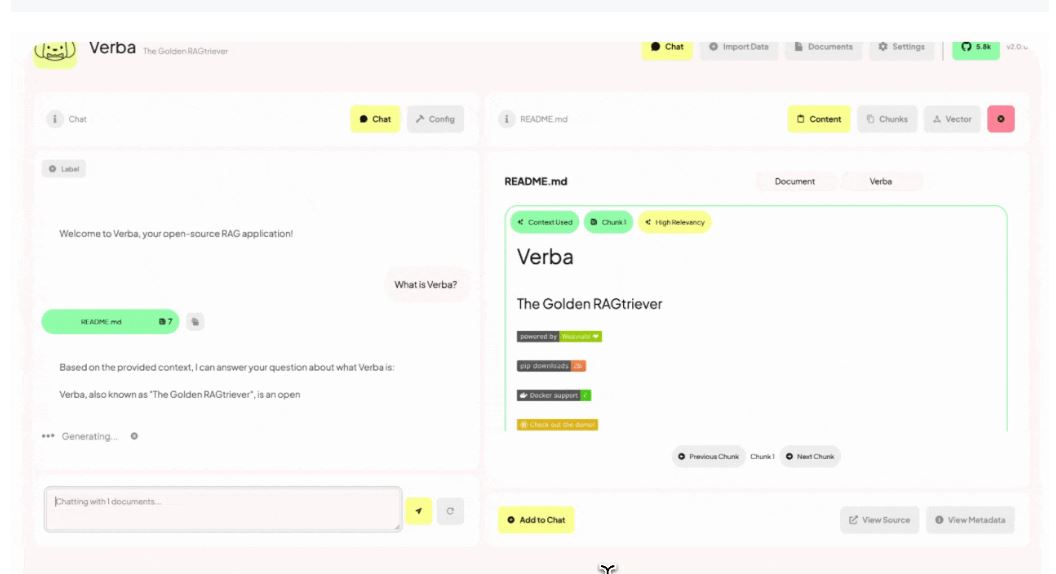
The Golden RAGtriever est une application open-source de Retrieval Augmented Generation (RAG) conçue pour vous permettre de créer rapidement des applications d'IA générative de type chatbot s'appuyant sur vos données ou base de connaissance d'entreprise.
Verba: The Golden RAGtriever est une suite d'application disponible sur Hugging Face, permettant de mettre en place un système de RAG.
Pour la téléchager: https://github.com/weaviate/Verba
Fonctionnalités avancées de
Gestion des données
- Importation en masse de fichiers via l'interface utilisateur ou l'API
- Prise en charge de formats variés : CSV, JSON, JSONL, TXT, PDF, DOCX, MD
- Possibilité d'ajouter des métadonnées personnalisées aux documents
- Système de tagging pour organiser et filtrer les documents
Moteur de recherche Weaviate
- Indexation vectorielle pour une recherche sémantique rapide
- Recherche hybride combinant recherche par mots-clés et similarité vectorielle
- Possibilité de configurer et d'ajuster les paramètres de recherche
Modèles de langage et IA
- Intégration flexible avec divers fournisseurs de LLM (Ollama, OpenAI, Anthropic, etc.)
- Possibilité d'utiliser des modèles locaux ou hébergés dans le cloud
- Paramétrage fin des prompts et des contextes pour optimiser les réponses
Interface utilisateur
- Dashboard intuitif pour la gestion des datasets et l'interaction avec l'assistant
- Visualisation des sources utilisées pour chaque réponse
- Historique des conversations et possibilité de sauvegarder des sessions
Fonctionnalités avancées
- Cache sémantique pour accélérer les réponses aux questions similaires
- Fonction "autocut" pour optimiser dynamiquement le nombre de résultats de recherche
- API RESTful pour l'intégration avec d'autres applications
Fonctionnement détaillé
1. Préparation des données :
- Les documents sont importés et convertis en texte brut si nécessaire
- Le texte est divisé en chunks (morceaux) de taille optimale pour l'indexation
2. Vectorisation et indexation :
- Chaque chunk est transformé en vecteur d'embedding par un modèle de langage
- Les vecteurs sont stockés dans Weaviate avec leurs métadonnées associées
3. Processus de requête :
- L'utilisateur pose une question via l'interface ou l'API
- La question est vectorisée et utilisée pour une recherche de similarité dans Weaviate
4. Recherche et récupération :
- Weaviate effectue une recherche hybride (vectorielle et par mots-clés)
- Les résultats les plus pertinents sont sélectionnés, avec ajustement automatique via "autocut"
5. Génération de réponse :
- Les chunks pertinents sont assemblés en un contexte
- Un prompt est construit, incluant la question et le contexte
- Le LLM génère une réponse basée sur ce prompt
6. Post-traitement et présentation :
- La réponse est formatée et enrichie avec les sources utilisées
- Le résultat est affiché à l'utilisateur, avec possibilité d'interactions supplémentaires
Ce processus permet à Verba de fournir des réponses précises et contextuelles, tout en offrant une grande flexibilité dans la configuration et l'utilisation du système.
Très bien, je vais maintenant vous guider à travers les étapes pour mettre en place un système de RAG avec Verba: The Golden RAGtriever. Voici un guide pas à pas :
Étape 1 : Installation et configuration
1. Cloner le dépôt GitHub de Verba :
```
git clone
cd Verba
```
2. Installer les dépendances :
```
pip install -r requirements.txt
```
3. Configurer les variables d'environnement :
- Créez un fichier `.env` à la racine du projet
- Ajoutez les clés API nécessaires (par exemple, pour OpenAI ou Anthropic)
Étape 2 : Préparation de la base de données Weaviate
1. Lancer Weaviate avec Docker :
```
docker-compose up -d
```
2. Vérifier que Weaviate est opérationnel en accédant à `
Étape 3 : Importation des données
1. Préparez vos fichiers de données dans un dossier dédié
2. Utilisez l'interface de ligne de commande de Verba pour importer les données :
```
python cli.py import --directory /chemin/vers/vos/donnees
```
3. Vérifiez que les données sont correctement indexées dans Weaviate
Étape 4 : Configuration du modèle de langage
1. Choisissez le modèle de langage que vous souhaitez utiliser (par exemple, GPT-3.5-turbo)
2. Configurez le modèle dans le fichier `config.yaml` :
```yaml
llm:
provider: openai
model: gpt-3.5-turbo
```
Étape 5 : Lancement de l'application
1. Démarrez l'application Verba :
```
python app.py
```
2. Accédez à l'interface utilisateur via `
Étape 6 : Personnalisation et optimisation
1. Ajustez les paramètres de recherche dans `config.yaml` :
```yaml
search:
limit: 10
alpha: 0.75
```
2. Personnalisez les prompts dans le fichier `prompts.py` pour affiner les réponses du modèle
3. Configurez le cache sémantique si nécessaire :
```yaml
cache:
enabled: true
expiration: 3600
```
Étape 7 : Test et itération
1. Posez des questions à travers l'interface utilisateur pour tester le système
2. Analysez les réponses et les sources utilisées
3. Ajustez les paramètres, les prompts ou les données si nécessaire pour améliorer les performances
Étape 8 : Intégration et déploiement (optionnel)
1. Utilisez l'API RESTful de Verba pour intégrer le système à d'autres applications
2. Déployez Verba sur un serveur ou un service cloud pour une utilisation en production
En suivant ces étapes, vous aurez mis en place un système de RAG fonctionnel avec Verba: The Golden RAGtriever. N'oubliez pas de consulter la documentation officielle pour des informations plus détaillées sur chaque étape et pour des options de configuration avancées.






