Les systèmes de gestion de base de données (SGBD) adaptés aux vecteurs sont particulièrement utiles pour les applications nécessitant des opérations sur des données vectorielles, comme l'apprentissage automatique, la recherche de similarité, ou la gestion de données géospatiales.
Voici une liste de SGBD spécialisés ou adaptés pour gérer des données vectorielles, puis une liste de base de données les plus adaptées à un système de RAG.
SGBD spécialisés pour les vecteurs
Weaviate
- Un SGBD open-source conçu pour les données vectorielles.
- Idéal pour la recherche sémantique et l'intégration avec des modèles de machine learning.
- Supporte des intégrations avec des modèles comme OpenAI, Hugging Face, etc.
Pinecone
- Un service de base de données vectorielles entièrement géré.
- Optimisé pour la recherche de similarité et les applications de machine learning.
- Supporte des index vectoriels à grande échelle.
Milvus
- Un SGBD open-source conçu pour la gestion et la recherche de données vectorielles.
- Utilisé pour des applications comme la recherche d'images, la reconnaissance faciale, et la recherche sémantique.
- Supporte des index avancés comme IVF, HNSW, et Annoy.
Qdrant
- Un SGBD vectoriel open-source et performant.
- Conçu pour la recherche de similarité et les applications de machine learning.
- Supporte des intégrations avec des frameworks comme TensorFlow et PyTorch.
Vespa
- Un moteur de recherche et de recommandation open-source qui supporte les données vectorielles.
- Idéal pour les applications de recherche en temps réel et de personnalisation.
Redis avec le module RedisAI ou Redisearch
- Redis peut être étendu avec des modules pour gérer des données vectorielles.
- RedisAI permet d'exécuter des modèles de machine learning, tandis que Redisearch supporte la recherche vectorielle.
FAISS (Facebook AI Similarity Search)
- Bien que ce ne soit pas un SGBD traditionnel, FAISS est une bibliothèque optimisée pour la recherche de similarité vectorielle.
- Souvent utilisé en combinaison avec d'autres systèmes pour gérer des index vectoriels.
Annoy (Approximate Nearest Neighbors Oh Yeah)
- Une bibliothèque développée par Spotify pour la recherche de voisins les plus proches.
- Utilisée pour des applications de recommandation et de recherche vectorielle.
SGBD traditionnels avec support vectoriel
PostgreSQL avec l'extension pgvector
- PostgreSQL peut être étendu avec pgvector pour gérer des données vectorielles.
- Idéal pour les applications nécessitant une intégration avec une base de données relationnelle.
Elasticsearch avec des plugins vectoriels
- Elasticsearch peut être utilisé pour la recherche vectorielle avec des plugins comme Elasticsearch Learning to Rank.
- Adapté pour des applications de recherche et d'analyse de données.
OpenSearch (fork d'Elasticsearch)
- Similaire à Elasticsearch, OpenSearch supporte également la recherche vectorielle.
SGBD pour données géospatiales (vecteurs 2D/3D)
PostGIS (extension de PostgreSQL)
- Spécialisé pour les données géospatiales vectorielles.
- Utilisé pour des applications de cartographie et de géolocalisation.
SpatiaLite (extension de SQLite)
- Une alternative légère pour gérer des données géospatiales vectorielles.
Choix en fonction de vos besoins
- Pour des applications de machine learning : Milvus, Pinecone, Weaviate.
- Pour une intégration avec des bases relationnelles : PostgreSQL + pgvector.
- Pour des données géospatiales : PostGIS, SpatiaLite.
- Pour des applications légères ou expérimentales : FAISS, Annoy.
Les meilleures bases de données pour un RAG
Pour un système de RAG (Retrieval-Augmented Generation), qui combine la recherche d'informations précises dans une base de données avec la génération de texte via des modèles de langage (comme GPT), il est crucial de choisir une base de données vectorielle performante et adaptée. Voici les meilleures options de bases de données vectorielles pour un système de RAG :
Pinecone
Adaptation à un RAG
Pinecone est une base de données vectorielle entièrement gérée, optimisée pour la recherche de similarité à grande échelle. Elle permet de stocker et d'interroger rapidement des embeddings vectoriels, ce qui est essentiel pour la phase de retrieval dans RAG.
Points forts
- Scalabilité et performance élevées.
- Intégration facile avec des frameworks de machine learning.
- Gestion des index vectoriels optimisés pour la recherche de similarité.
- Site officiel :
Weaviate
Adaptation à un RAG
Weaviate est une base de données vectorielle open-source qui supporte la recherche sémantique et peut être intégrée directement avec des modèles de langage comme OpenAI ou Hugging Face. Il est conçu pour des applications de recherche et de recommandation.
Points forts
- Recherche sémantique et hybridation (combinaison de recherche vectorielle et textuelle).
- Intégration native avec des modèles de machine learning.
- Extensible et personnalisable.
- Site officiel :
Milvus
Adaptation à un RAG
Milvus est une base de données vectorielle open-source conçue pour la gestion et la recherche de données vectorielles à grande échelle. Elle est largement utilisée pour des applications de recherche de similarité et de recommandation.
Points forts
- Supporte des index avancés comme HNSW, IVF, et Annoy.
- Scalabilité horizontale pour de grands volumes de données.
- Communauté active et documentation complète.
- Site officiel :
Qdrant
Adaptation à un RAG
Qdrant est une base de données vectorielle open-source, performante et facile à utiliser. Elle est optimisée pour la recherche de similarité et peut être intégrée avec des modèles de langage pour des applications RAG.
Points forts
- Performances élevées avec un faible temps de latence.
- API simple et bien documentée.
- Supporte des intégrations avec des frameworks comme TensorFlow et PyTorch.
- Site officiel :
Vespa
Adaptation à un RAG
Vespa est un moteur de recherche et de recommandation open-source qui supporte les données vectorielles. Il est conçu pour des applications en temps réel et peut être utilisé pour la phase de retrieval dans RAG.
Points forts
- Recherche hybride (texte + vecteurs).
- Scalabilité et performances élevées.
- Intégration avec des modèles de machine learning.
- Site officiel :
FAISS (Facebook AI Similarity Search)
Adaptation à un RAG
FAISS est une bibliothèque open-source développée par Facebook pour la recherche de similarité vectorielle. Bien que ce ne soit pas une base de données traditionnelle, elle est largement utilisée pour des applications de recherche de similarité.
Points forts
- Optimisé pour la recherche de voisins les plus proches (k-NN).
- Très performant pour des datasets de grande taille.
- Intégration facile avec des pipelines de machine learning.
- Site officiel :
Redis avec Redisearch ou RedisAI
Adaptation à un RAG
Redis peut être étendu avec des modules comme Redisearch (pour la recherche textuelle et vectorielle) ou RedisAI (pour exécuter des modèles de machine learning). Il est idéal pour des applications nécessitant une faible latence.
Points forts
- Faible latence et haute performance.
- Supporte la recherche hybride (texte + vecteurs).
- Facile à intégrer dans des systèmes existants.
- Site officiel :
Elasticsearch avec des plugins vectoriels
Adaptation à un RAG
Elasticsearch peut être utilisé pour la recherche vectorielle avec des plugins comme Elasticsearch Learning to Rank. Il est adapté pour des applications de recherche et d'analyse de données.
Points forts
- Recherche hybride (texte + vecteurs).
- Scalabilité et performances élevées.
- Large écosystème et communauté.
- Site officiel :
Comparaison des bases de données RAG
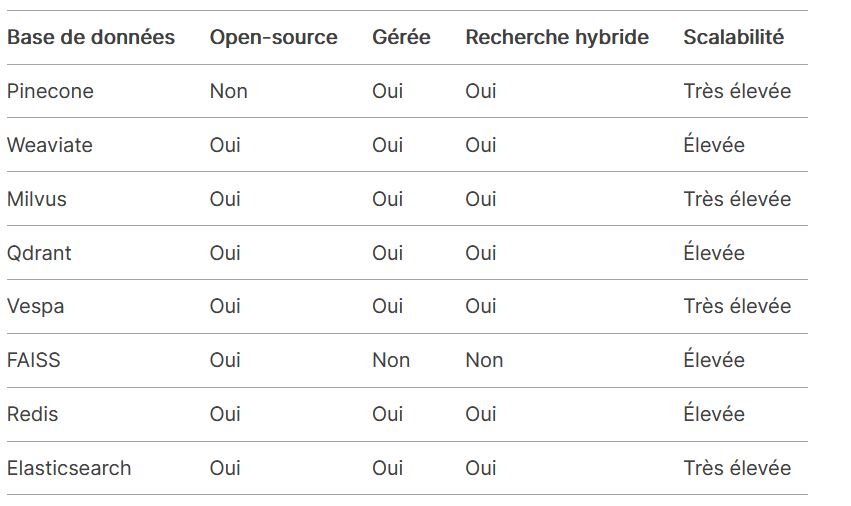
Nos conseils
Pour un système RAG, Pinecone, Weaviate, et Milvus sont parmi les meilleurs choix en raison de leur intégration native avec des modèles de langage et leur capacité à gérer des recherches de similarité à grande échelle.
Si vous préférez une solution open-source, Qdrant ou Milvus sont excellents.
Pour des applications nécessitant une faible latence, Redis est une option solide.
Le choix final dépendra de vos besoins spécifiques en termes de scalabilité, de budget, et d'intégration avec votre infrastructure existante.






