4 briques clés pour une gestion des données efficace en entreprise
La gestion des données est devenue un enjeu et un défi à l'ère du Big Data, car les entreprises accumulent des informations de toute part, sans savoir quoi en faire et surtout comment le faire. La solution : construire une modern data stack.
Bien exploitées, les données peuvent renforcer la prise de décision, améliorer l'efficacité opérationnelle et générer un réel avantage concurrentiel. À l'inverse, mal gérées, elles stagnent dans des silos, perdent en qualité et restent sous-utilisées. Pour transformer cet actif en levier stratégique, de plus en plus d'entreprises s'orientent vers une architecture moderne et évolutive : la Modern Data Stack. Cette approche marque un tournant en plaçant la donnée au cœur des usages métiers, et non plus uniquement au sein des équipes techniques.
Dans cet article, nous décrirons quatre briques clés pour une gestion efficace des données en entreprise :
- Construire une architecture moderne et évolutive,
- Centraliser les sources d'information
- Instaurer une gouvernance et une qualité des données rigoureuses
- Activer et utiliser la donnée de façon opérationnelle et stratégique.
Construire une architecture solide avec une Modern Data Stack évolutive
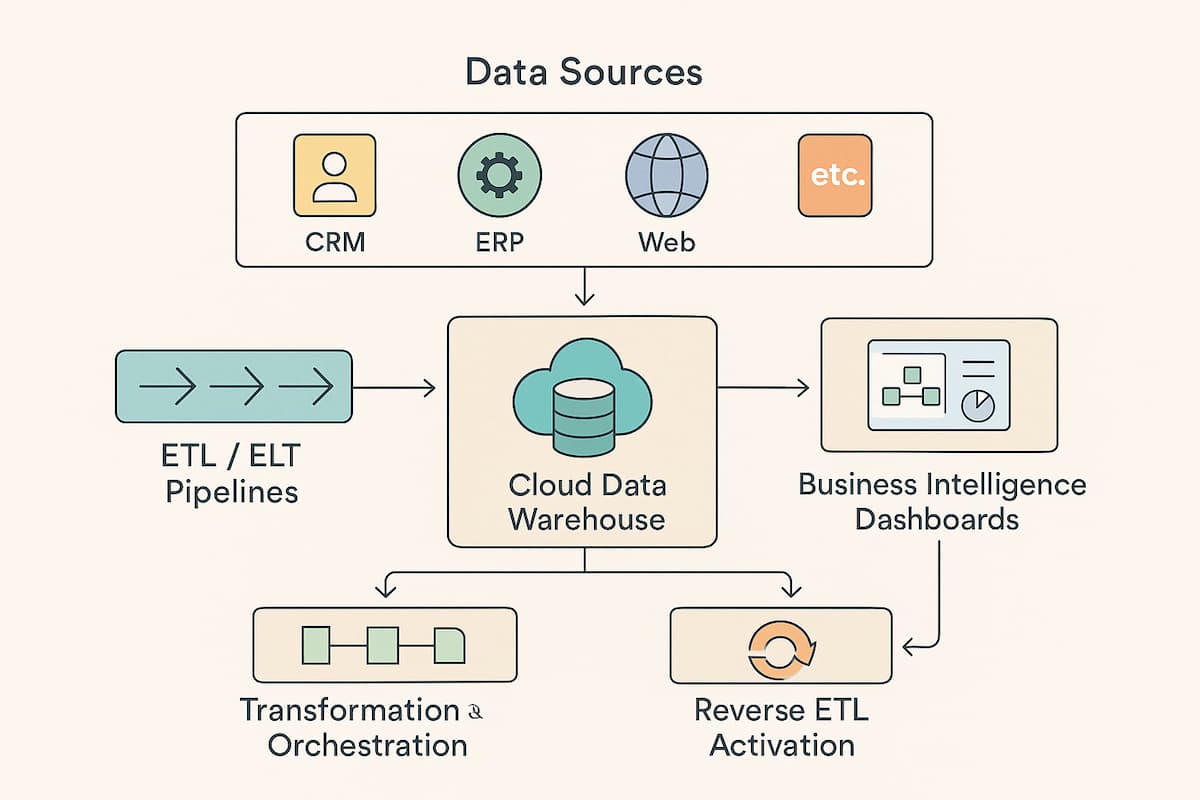
La base d'une gestion de données efficace repose sur une architecture technique flexible et évolutive. Pour cela, l'une des approches les plus performantes consiste à construire une Modern Data Stack, en combinant des outils spécialisés pour chaque étape du cycle de vie des données. Cette structure modulaire permet d'adapter ou de remplacer chaque brique sans remettre en cause l'ensemble du système. Elle assure ainsi agilité, scalabilité et cohérence dans le temps.
Entrepôt de données cloud (data warehouse)
Le point de départ d'une Modern Data Stack efficace repose sur un entrepôt de données cloud. Véritable socle central, ce stockage sert de référentiel unique pour toutes les données de l'entreprise. En tant que « single source of truth », il garantit une base fiable pour l'ensemble des analyses, visualisations et actions opérationnelles. Pour répondre aux besoins croissants en volume et en complexité, cet entrepôt doit être à la fois performant, évolutif et sécurisé.
Outils d'intégration de données (ETL/ELT)
Une fois l'entrepôt en place, vous devez y acheminer la donnée de manière structurée. C'est là qu'interviennent les outils d'intégration (ETL ou ELT), qui automatisent l'extraction des données issues de diverses sources (CRM, ERP, applications métiers, etc.), leur transformation si nécessaire, puis leur chargement dans l'entrepôt. Ce processus permet d'unifier l'information tout en préservant l'historique, indispensable pour les analyses rétrospectives et la traçabilité.
Orchestrateur de flux de données
Pour garantir la cohérence et la régularité de ces flux, un outil d'orchestration des données vient piloter l'exécution des pipelines. Il planifie, supervise et coordonne chaque étape du traitement de la donnée, en gérant les dépendances et en automatisant les tâches récurrentes. Grâce à l'orchestration, les interventions manuelles sont réduites au minimum, et les risques d'erreurs ou de ruptures de flux sont fortement diminués, même à grande échelle.
Outils d'activation et d'analyse
Une fois les données centralisées et fiables, il est temps de les exploiter. Les outils de Business Intelligence (BI) permettent aux équipes de visualiser l'information à travers des tableaux de bord interactifs, facilitant ainsi la prise de décisions éclairées. En parallèle, les solutions d'activation des données, comme le Reverse ETL, rendent possible le renvoi des données enrichies vers les outils opérationnels (marketing, ventes, support). Cela permet d'automatiser des actions métier ciblées, directement fondées sur les données consolidées, et ainsi de passer de l'analyse à l'action.
Centraliser les sources d'information pour garantir une donnée unifiée
Le fait de centraliser la donnée est devenu un enjeu stratégique pour les entreprises qui souhaitent améliorer leur efficacité opérationnelle. Une information fragmentée ralentit les décisions, crée des incohérences et nuit à la performance globale. Nous vous expliquons pourquoi l'unification des sources est indispensable.
Supprimer les silos pour créer une source unique de vérité
Même avec la meilleure architecture technique, la valeur de la donnée dépend, en partie, de votre capacité à l'unifier. Or, dans de nombreuses entreprises, l'information reste éparpillée entre différents logiciels et bases (outils CRM, ERP, site e-commerce, plateformes de campagnes emailing, etc.). Cette fragmentation crée des silos de données hétérogènes qui compliquent ou empêchent une vision globale. La deuxième clé d'une gestion efficace consiste donc à centraliser toutes les sources de données au sein d'un système unique afin de garantir une vue unifiée et cohérente.
Centraliser les données implique d'intégrer l'information en provenance de chaque brique système dans un entrepôt commun, en harmonisant les formats et les schémas de données au passage. L'objectif est d'établir, ce que l'on appelle, « source unique de vérité » pour l'entreprise — c'est-à-dire une base centrale faisant foi, à partir de laquelle chaque département puise ses indicateurs. Cette centralisation est indispensable pour permettre des analyses transversales et cohérentes sur l'ensemble de l'activité de l'entreprise. Elle garantit qu'un même indicateur (par exemple le chiffre d'affaires client) est calculé de façon identique, quel que soit le service qui le consulte, éliminant ainsi les discordances entre chiffres.
Intégration technique et bénéfices métiers
Techniquement, la mise en place d'un tel référentiel passe par des processus d'intégration robustes. Des connecteurs ETL/ELT vont extraire automatiquement les données de toutes les applications sources et les charger dans l'entrepôt cloud central. Ce processus d'unification apporte plusieurs bénéfices majeurs. Le fait de consolider toutes les données dans un même environnement offre d'abord une vision à 360° de l'activité (vue client unifiée, suivi bout-en-bout des opérations, etc.). La centralisation améliore ensuite la productivité data en évitant les tâches redondantes de recherche et de rapprochement de données issues de systèmes différents. Vous pouvez enfin conserver un historique complet des données, précieux pour analyser les tendances sur le long terme ou répondre à des obligations d'audit.
Une fois la donnée centralisée et nettoyée, elle peut être mise à disposition de l'ensemble des collaborateurs par des outils d'accès adaptés :
- requêtes SQL,
- interfaces BI,
- API,
- interfaces conversationnelles…
Idéalement, les flux d'alimentation de l'entrepôt sont suffisamment fréquents pour fournir des informations en quasi-temps réel aux équipes métier. Que ce soit un analyste marketing cherchant le dernier taux de conversion d'un point de vente ou un commercial consultant la fiche actualisée d'un client, chacun accède ainsi à des données à jour, fiables et cohérentes. En éliminant les silos et les latences d'accès, l'entreprise gagne en réactivité et en cohésion autour de la donnée.

Mettre en place des règles de gouvernance et de qualité des données
Le fait de centraliser et d'outiller la donnée ne suffit pas. Vous devez vous assurer que cette donnée soit fiable, bien gérée et conforme aux règles. C'est ici qu'intervient la gouvernance des données, troisième pilier d'une gestion efficace. La gouvernance regroupe l'ensemble des politiques, procédures et responsabilités définies pour encadrer l'utilisation des données au sein de l'entreprise. Elle vise à garantir que la donnée demeure un actif fiable, traçable et conforme tout au long de son cycle de vie.
Rôles et responsabilités clairs
Une gouvernance des données efficace commence par une répartition précise des rôles. Désignez des responsables par domaine de données, comme les data owners ou data stewards, afin de structurer la gestion au quotidien. Chaque collaborateur doit savoir précisément quelles données il peut consulter, modifier ou partager. Cette clarté renforce à la fois la responsabilisation individuelle et la sécurité globale du système.
Pour aller plus loin, la mise en place de contrôles d'accès robustes — authentification, restrictions par rôle, permissions spécifiques — permet de protéger les informations sensibles et de limiter les risques de fuites ou d'erreurs humaines.
Qualité et validation des données
Une fois les responsabilités définies, la qualité de la donnée devient un enjeu central. Mettez en place des contrôles automatiques pour détecter les anomalies ou incohérences dès leur apparition. Des outils de monitoring et de data quality permettent de vérifier en continu l'intégrité des jeux de données et d'alerter en cas de déviation par rapport aux standards définis. Chaque flux de données devrait intégrer des étapes de validation, telles que le comptage d'enregistrements ou la vérification de formats, garantissant ainsi que les données ingérées sont fiables et exploitables sans risque.
Documentation et traçabilité
Pour rendre l'écosystème data compréhensible et exploitable par tous, la documentation joue un rôle clé. Elle doit être centralisée dans un catalogue de données, accessible aux équipes concernées. Ce catalogue recense l'origine, la signification, la structure et les métadonnées associées à chaque jeu de données. Il facilite la compréhension des informations manipulées, tout en assurant la traçabilité des modifications. Cette visibilité est précieuse pour les projets en cours. Elle offre la possibilité de répondre aux audits, d'effectuer des analyses de qualité ou encore de corriger des erreurs de traitement en toute transparence.
Conformité réglementaire
Aucune gouvernance de la donnée ne peut enfin être complète sans une attention portée à la conformité réglementaire. Respecter les cadres juridiques comme le RGPD, l'HIPAA ou d'autres normes sectorielles est incontournable. Cela implique de gérer les consentements des utilisateurs, de maîtriser les durées de conservation des données personnelles et de choisir des technologies compatibles avec ces exigences.
Le fait d'intégrer la conformité dès la phase de conception (Privacy by Design) aide à éviter des réajustements coûteux par la suite et à limiter les risques juridiques. Une architecture pensée pour la conformité protège à la fois l'entreprise et ses utilisateurs.
Exploiter la donnée de façon opérationnelle et stratégique
La dernière pièce du puzzle — et non la moindre — est enfin l'exploitation effective des données à tous les niveaux de l'entreprise. Une fois que vous disposez de données unifiées, de qualité et gouvernées, mettez-les en action pour créer de la valeur, tant sur le plan opérationnel (les activités courantes) que stratégique (l'orientation de l'entreprise à long terme).
Mettre la donnée au service des opérations quotidiennes
Sur le plan opérationnel, les données doivent éclairer les décisions du quotidien. Pour cela, les entreprises déploient des tableaux de bord dynamiques et autres rapports qui fournissent aux équipes terrain des indicateurs à jour.
Grâce aux outils de BI modernes, la création de tels tableaux de bord est devenue plus agile et accessible, même pour des utilisateurs non techniques. Des solutions comme Looker Studio ou Power BI permettent par exemple de bâtir des rapports interactifs en quelques heures seulement, sans avoir à coder en SQL.
Chaque service (marketing, ventes, production…) peut ainsi suivre ses KPIs clés presque en temps réel et ajuster ses actions en conséquence. L'impact sur la réactivité est immédiat : les managers disposent d'une visibilité accrue pour piloter leurs équipes. Les décisions se fondent sur des faits tangibles plutôt que sur de simples intuitions.
Activer les données pour guider les choix stratégiques
Sur le versant stratégique, l'enjeu est d'aller au-delà de la visualisation pour réellement activer la donnée dans les processus métier. Utilisez les informations disponibles pour automatiser des scénarios et personnaliser les interactions avec les clients.
C'est ici qu'interviennent des outils d'activation comme le Reverse ETL, qui envoient les segments de données consolidées depuis l'entrepôt de données vers les applications opérationnelles de l'entreprise. Concrètement, cela permet par exemple de synchroniser automatiquement des listes de clients cibles depuis le data warehouse vers une plateforme d'emailing ou un CRM, afin de déclencher des campagnes marketing personnalisées sans intervention manuelle.
Les cas d'usage rendus possibles par ce type d'outil sont multiples pour les équipes marketing, CRM, ventes ou support, le tout sans nécessiter de développer de code spécifique. La data activée vient ainsi alimenter directement l'action. Elle sert à prioriser des leads commerciaux, à recommander le bon produit au bon client au bon moment, ou encore à déclencher des alertes internes si un indicateur critique passe en anomalie.
Exploiter la donnée de manière transversale pour innover
En utilisant la donnée de façon transversale, l'entreprise transforme celle-ci en un véritable levier d'amélioration continue. Les insights tirés des analyses alimentent la réflexion stratégique :
- identification de nouvelles tendances marché,
- compréhension plus fine des comportements clients,
- optimisation de l'offre de produits ou services en fonction des usages observés, etc.
L'étude des données peut par exemple révéler qu'une fonctionnalité logicielle peu utilisée freine l'adoption d'un produit, conduisant l'équipe produit à la repenser. De même, une analyse des parcours clients peut inspirer de nouvelles approches marketing ciblées.
À terme, cette exploitation stratégique des données se traduit par des gains de performance significatifs. Une Modern Data Stack pleinement mise en œuvre offre en effet une gestion plus efficiente et flexible des données, et les bénéfices potentiels pour l'entreprise sont immenses. En faisant de la donnée un atout opérationnel et concurrentiel, l'entreprise renforce son agilité et sa capacité à innover sur son marché.










