Machine de Boltzmann restreinte
Une machine de Boltzmann restreinte (RBM) est un réseau neuronal artificiel stochastique génératif pouvant apprendre une distribution de probabilité sur son ensemble d'entrées.
Les machines de Boltzmann restreinte ont d’abord été inventé sous le nom Harmonium par Paul Smolensky en 1986, et accède à la notoriété après Geoffrey Hinton et collaborateurs Invente d algorithmes d'apprentissage rapide pour eux dans le milieu de 2000. Les machines de Boltzmann restreinte ont trouvé des applications dans la réduction de dimensionnalité, classification, le filtrage collaboratif, l’apprentissage des fonctionnalités, modélisation sujet et même beaucoup de mécanique quantique du corps. Ils peuvent être formés de manière supervisée ou non, en fonction de la tâche.
Comme leur nom l’indique, les machines de Boltzmann restreinte sont une variante de la machine de Boltzmann s, avec la restriction que leurs neurones doivent former un bip graphique de artite : une paire de noeuds à partir de chacun des deux groupes d'unités (communément appelé le « visible » et " "cachés" respectivement) peuvent avoir une connexion symétrique entre eux; et il n'y a pas de connexion entre les nœuds d'un groupe.
En revanche, les machines Boltzmann "sans restriction" peuvent avoir des connexions entre des unités cachées. Cette restriction permet d'obtenir des algorithmes d'entraînement plus efficaces que ceux disponibles pour la classe générale des machines de Boltzmann, en particulier l’algorithme de divergence contrastive basé sur un gradient.
Les machines Boltzmann restreintes peuvent également être utilisées dans des réseaux d’apprentissage en profondeur. En particulier, des réseaux de croyance profonds peuvent être formés en "empilant" des machines de Boltzmann restreinte et en ajustant éventuellement le réseau profond résultant avec une descente de gradient et une rétropropagation.
Une machine Boltzmann, comme un réseau Hopfield, est un réseau d'unités avec une " énergie " (hamiltonienne) définie pour l'ensemble du réseau. Ses unités produisent des résultats binaires. Contrairement aux réseaux de Hopfield, les unités des machines Boltzmann sont stochastiques. L'énergie globale E {\displaystyle E} E dans une machine Boltzmann est identique dans sa forme à celle d'un réseau Hopfield ainsi qu'au modèle Ising :
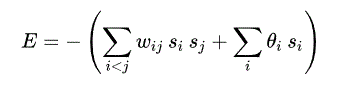
Où :
w i j est la force de connexion entre l'unité j j et l'unité i
s i est l'état, s i ∈ { 0 , 1 }, de l'unité i .
θ i est le biais de l'unité i dans la fonction d'énergie globale. ( - θ i est le seuil d'activation de l'unité).
Souvent, les poids w i j sont représentés sous la forme d'une matrice symétrique W = [ w i j ] avec des zéros le long de la diagonale.
Probabilité d'état unitaire
La différence d'énergie globale qui résulte d'une seule unité i égale 0 (off) contre 1 (on), écrit Δ E i , en supposant une matrice symétrique de poids, est donnée par :
Δ E i = ∑ (j > i) w i j s j + ∑ (j < i) w j i s j + θ i
Cela peut être exprimé comme la différence des énergies de deux états :
Δ E i = E i=off - E i=on
La substitution de l'énergie de chaque état par sa probabilité relative selon le facteur de Boltzmann (la propriété d'une distribution de Boltzmann que l'énergie d'un état est proportionnelle à la probabilité logarithmique négative de cet état) donne :
Δ E i = - k B T ln ( p i=off ) - ( - k B T ln ( p i=on ) )
où k B est la constante de Boltzmann et est absorbée dans la notion artificielle de température T . Nous réorganisons ensuite les termes et considérons que les probabilités que l'unité soit en marche et à l'arrêt doivent s'additionner à un :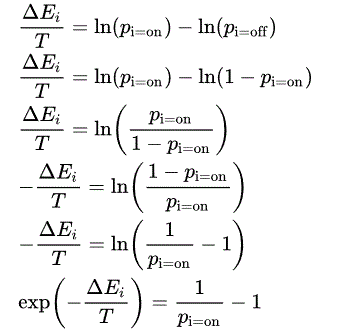
En résolvant p i=on, on obtient la probabilité que la i-ème unité soit allumée :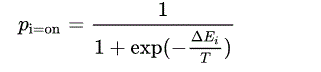
où le scalaire T T est la température du système. Cette relation est la source de la fonction logistique que l'on retrouve dans les expressions de probabilité des variantes de la machine de Boltzmann.
État d'équilibre
Le réseau fonctionne en sélectionnant une unité de façon répétée et en réinitialisant son état. Après avoir fonctionné assez longtemps à une certaine température, la probabilité d'un état global du réseau ne dépend que de l'énergie de cet état global, selon une distribution de Boltzmann, et non de l'état initial à partir duquel le processus a été lancé. Cela signifie que les log-probabilités des états globaux deviennent linéaires dans leurs énergies. Cette relation est vraie lorsque la machine est "à l'équilibre thermique", ce qui signifie que la distribution des probabilités des états globaux a convergé. En faisant fonctionner le réseau à partir d'une température élevée, sa température diminue progressivement jusqu'à atteindre un équilibre thermique à une température plus basse. Elle peut alors converger vers une distribution où le niveau d'énergie fluctue autour du minimum global. Ce processus est appelé recuit simulé.
Pour entraîner le réseau afin que la probabilité qu'il converge vers un état global soit selon une distribution externe sur ces états, les poids doivent être réglés de façon à ce que les états globaux ayant les plus grandes probabilités obtiennent les énergies les plus faibles. Cela se fait par l'entraînement.
Entrainement
Les unités de la machine Boltzmann sont divisées en unités "visibles", V, et en unités "cachées", H. Les unités visibles sont celles qui reçoivent des informations de l'"environnement", c'est-à-dire que l'ensemble d'apprentissage est un ensemble de vecteurs binaires sur l'ensemble V. La distribution sur l'ensemble d'apprentissage est désignée par P + ( V )
Comme nous l'avons vu plus haut, la distribution sur les états globaux converge lorsque la machine de Boltzmann atteint l'équilibre thermique. Nous désignons cette distribution, après l'avoir marginalisée sur les unités cachées, comme P - ( V ) P^{-}(V).
Notre but est d'approcher la distribution "réelle" P + ( V ) en utilisant le style d'affichage P - ( V ) produit (éventuellement) par la machine. Pour mesurer la similarité des deux distributions, la divergence de Kullback-Leibler, G est
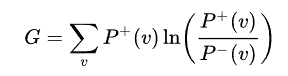
où la somme est supérieure à tous les états possibles de V {\displaystyle V} V. G G est une fonction des poids, puisqu'ils déterminent l'énergie d'un état, et que l'énergie détermine P - ( v ) P^{-}(v), comme promis par la distribution Boltzmann. On peut donc utiliser un algorithme de descente de gradient sur G , donc un poids donné, w i j est changé en soustrayant la dérivée partielle de G . G par rapport au poids.
L'entraînement sur machine Boltzmann se déroule en deux phases alternées. L'une est la phase "positive" où les états des unités visibles sont fixés à un vecteur d'état binaire particulier échantillonné à partir de l'ensemble d'apprentissage (selon P +). L'autre phase est la phase "négative" où le réseau est autorisé à fonctionner librement, c'est-à-dire qu'aucune unité n'a son état déterminé par des données externes. De façon surprenante, le gradient par rapport à un poids donné, w i j , est donné par l'équation simple et éprouvée :
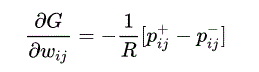
où :
p i j + est la probabilité que les unités i et j soient toutes les deux allumées lorsque la machine est à l'équilibre sur la phase positive.
p i j - est la probabilité que les unités i et j soient toutes les deux activées lorsque la machine est à l'équilibre sur la phase négative.
R indique le taux d'apprentissage
Ce résultat découle du fait qu'à l'équilibre thermique, la probabilité P - ( s ) de tout état global s lorsque le réseau est libre est donné par la distribution Boltzmann (d'où le nom "machine Boltzmann").
Remarquablement, cette règle d'apprentissage est assez plausible biologiquement car la seule information nécessaire pour changer les poids est fournie par l'information "locale". C'est-à-dire que la connexion (ou synapse, biologiquement parlant) n'a pas besoin d'information sur autre chose que les deux neurones qu'elle relie. C'est beaucoup plus réaliste sur le plan biologique que l'information nécessaire à une connexion dans de nombreux autres algorithmes d'entraînement des réseaux neuronaux, comme la rétropropagation.
L'entraînement d'une machine de Boltzmann n'utilise pas l'algorithme EM, qui est très utilisé dans l'apprentissage machine. En minimisant la divergence KL, cela équivaut à maximiser la log-vraisemblance des données. Par conséquent, la procédure d'apprentissage effectue une ascension de gradient sur la log-vraisemblance des données observées. Ceci est à l'opposé de l'algorithme EM, où la distribution postérieure des nœuds cachés doit être calculée avant la maximisation de la valeur attendue de la vraisemblance complète des données pendant l'étape M.
L'apprentissage des biais est similaire, mais n'utilise que l'activité d'un seul nœud :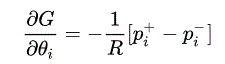
Problèmes
La machine de Boltzmann serait théoriquement un moyen de calcul assez général. Par exemple, si elle était entraînée sur des photographies, la machine modéliserait théoriquement la distribution des photographies et pourrait utiliser ce modèle pour, par exemple, compléter une photographie partielle.
Malheureusement, la machine Boltzmann présente un sérieux problème pratique, à savoir qu'elle semble cesser d'apprendre correctement lorsque la machine est mise à l'échelle pour devenir quelque chose de plus grand qu'une machine triviale [citation nécessaire]. Cela est dû à un certain nombre d'effets, dont les plus importants sont
- le temps de fonctionnement de la machine pour collecter les statistiques d'équilibre croît exponentiellement avec la taille de la machine, et avec l'ampleur des forces de connexion [citation nécessaire]
- Les forces de connexion sont plus plastiques lorsque les unités à connecter ont des probabilités d'activation intermédiaires entre zéro et un, ce qui conduit à ce que l'on appelle un piège à variance. L'effet net est que le bruit fait que les forces de connexion suivent une marche aléatoire jusqu'à saturation des activités.
Types
Machine Boltzmann restreinte
Représentation graphique d'un exemple de machine Boltzmann restreinte
Représentation graphique d'une machine Boltzmann restreinte. Les quatre unités bleues représentent les unités cachées, et les trois unités rouges représentent les états visibles. Dans les machines Boltzmann restreintes, il n'y a que des connexions (dépendances) entre les unités visibles et cachées, et aucune entre les unités du même type (pas de connexions visibles ou cachées).
Article principal : Machine Boltzmann restreinte
Bien que l'apprentissage ne soit pas pratique dans les machines Boltzmann générales, il peut être rendu très efficace dans une architecture appelée " machine Boltzmann restreinte " ou " RBM " qui ne permet pas de connexions intralayer entre les unités cachées. Après la formation d'une RBM, les activités de ses unités cachées peuvent être traitées comme des données pour la formation d'une RBM de niveau supérieur. Cette méthode d'empilement des RBMs permet de former efficacement de nombreuses couches d'unités cachées et constitue l'une des stratégies d'apprentissage profond les plus courantes. A mesure que chaque nouvelle couche est ajoutée, le modèle génératif global s'améliore.
Il existe une extension à la machine Boltzmann restreinte qui permet d'utiliser des données réelles valorisées plutôt que des données binaires. Elle est décrite ici, ainsi que les machines de Boltzmann d'ordre supérieur.
Un exemple d'application pratique des machines Boltzmann restreintes est l'amélioration des performances des logiciels de reconnaissance vocale.
Machine de Boltzmann profonde
Une machine de Boltzmann profonde (DBM) est un type de champ aléatoire binaire de Markov par paires (modèle graphique probabiliste non dirigé) avec plusieurs couches de variables aléatoires cachées. C'est un réseau d'unités binaires stochastiques couplées symétriquement. Il comprend un ensemble d'unités visibles ν ∈ { 0 , 1 } Le symbole en gras de D et des couches d'unités cachées h ( 1 ) ∈ { 0 , 1 } F 1 , h ( 2 ) ∈ { 0 , 1 } F 2 , ... , h ( L ) ∈ { 0 , 1 } F L
Aucune connexion ne relie les unités de la même couche (comme RBM). Pour la DBM, la probabilité assignée au vecteur ν est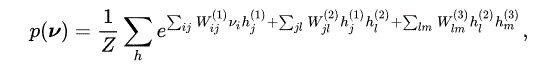
où ![]() sont les unités cachées, et
sont les unités cachées, et ![]()
Dans un DBN, seules les deux couches supérieures forment une machine de Boltzmann restreinte (qui est un modèle graphique non dirigé), tandis que les couches inférieures forment un modèle génératif dirigé. Dans un DBM, toutes les couches sont symétriques et non dirigées.
Comme les DBN, les DBM peuvent apprendre des représentations internes complexes et abstraites de l'entrée dans des tâches telles que la reconnaissance d'objets ou de la parole, en utilisant des données limitées et étiquetées pour affiner les représentations construites à l'aide d'une grande quantité de données d'entrée sensorielles non étiquetées. Cependant, contrairement aux DBN et aux réseaux neuronaux convolutionnels profonds, ils adoptent la procédure d'inférence et d'apprentissage dans les deux sens, passe ascendante et descendante, ce qui permet à la machine de Boltzmann profond de mieux dévoiler les représentations des structures d'entrée.
Cependant, la lenteur des DBMs limite leurs performances et leurs fonctionnalités. Étant donné que l'apprentissage exact du maximum de vraisemblance est difficile à réaliser pour les SGBD, seul un apprentissage approximatif du maximum de vraisemblance est possible. Une autre option consiste à utiliser l'inférence de champ moyen pour estimer les attentes dépendantes des données et à approximer les statistiques suffisantes attendues en utilisant la chaîne de Markov Monte Carlo (MCMC)[8]. Cette inférence approximative, qui doit être faite pour chaque entrée de test, est environ 25 à 50 fois plus lente qu'un seul passage ascendant dans les MDB. Cela rend l'optimisation conjointe peu pratique pour les grands ensembles de données et restreint l'utilisation des MDB pour des tâches telles que la représentation des caractéristiques.
Les RBM Spike and Slab
La nécessité d'un apprentissage approfondi avec des entrées à valeur réelle, comme dans les machines Boltzmann à restriction gaussienne, a conduit à la RBM à pic et à dalle (ssRBM), qui modélise des entrées à valeur continue avec des variables latentes strictement binaires. Comme les RBM de base et leurs variantes, une RBM à pic et à dalle est un graphique bipartite, tandis que comme les GRBM, les unités visibles (entrée) sont à valeur réelle. La différence se situe dans la couche cachée, où chaque unité cachée a une variable binaire de pointe et une variable de dalle à valeur réelle. Un pic est une masse de probabilité discrète à zéro, tandis qu'une dalle est une densité sur un domaine continu ; leur mélange forme un antécédent.
Une extension de ssRBM appelée µ-ssRBM fournit une capacité de modélisation supplémentaire en utilisant des termes supplémentaires dans la fonction énergétique. L'un de ces termes permet au modèle de former une distribution conditionnelle des variables de pointe en marginalisant les variables de la dalle, compte tenu d'une observation.
Histoire
La machine Boltzmann est basée sur un modèle de spin-glass du modèle d'Ising stochastique de Sherrington-Kirkpatrick
David Sherrington et Scott Kirkpatrick, modèle résoluble d'une vitre tournante, Phys. rév. 35, 1792 (1975)
Cependant, une contribution originale dans l'application d'un tel modèle basé sur l'énergie en science cognitive est apparue dans l'article initial suivant,
Geoffrey E. Hinton et Terrence J. Sejnowski, Analyser le calcul coopératif. Dans les Actes du 5e Congrès annuel de la Cognitive Science Society, Rochester, New York, mai 1983.
Geoffrey E. Hinton et Terrence J. Sejnowski, Optimal Perceptual Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 448-453, IEEE Computer Society, Washington, D.C., juin 1983.
Cependant, ces articles sont parus après la publication de John Hopfield, qui a fait autorité en la matière, où le lien avec la physique et la mécanique statistique a été établi en premier lieu, en mentionnant les verres de spin :
John J. Hopfield, Neural networks and physical systems with emergent collective computational abilities, Proc. Natl. Acad. Sci. USA, vol. 79 no. 8, p. 2554-2558, avril 1982.
L'idée d'appliquer le modèle d'Ising avec un échantillonnage de Gibbs recuit est également présente dans le projet Copycat de Douglas Hofstadter :
Hofstadter, Douglas R., The Copycat Project : The Copycat Project : An Experiment in Nondeterminism and Creative Analogies. MIT Artificial Intelligence Laboratory Memo No. 755, janvier 1984.
Hofstadter, Douglas R., A Non-Deterministic Approach to Analogy, Involving the Ising Model of Ferromagnetism. Dans E. Caianiello, éd. The Physics of Cognitive Processes. Teaneck, New Jersey : World Scientific, 1987.
Des idées similaires (avec un changement de signe dans la fonction énergétique) se retrouvent également dans la "Théorie de l'Harmonie" de Paul Smolensky.
L'analogie explicite établie avec la mécanique statistique dans la formulation de la machine de Boltzmann a conduit à l'utilisation d'une terminologie empruntée à la physique (par exemple, " énergie " plutôt que " harmonie "), qui est devenue la norme dans le domaine. L'adoption généralisée de cette terminologie a peut-être été encouragée par le fait que son utilisation a conduit à l'importation de divers concepts et méthodes de la mécanique statistique. Toutefois, il n'y a aucune raison de penser que les diverses propositions d'utilisation du recuit simulé pour l'inférence décrites ci-dessus n'étaient pas indépendantes. (Helmholtz a fait une analogie similaire à l'aube de la psychophysique).
Les modèles d'Ising sont maintenant considérés comme un cas spécial de champs aléatoires de Markov, qui trouvent une application répandue dans divers domaines, dont la linguistique, la robotique, la vision par ordinateur et l'intelligence artificielle.

