Comment devenir ingénieur data en 2022 en autoformation

Vous souhaitez vous (re)convertir et devenir ingénieur data sans suivre de cours en institut ou école ? Voici tous les savoir-faire à maitriser et les sites qui vont avec.
Le monde de la data science évolue, et il change rapidement. Dans le bon vieux temps, toutes vos données étaient facilement disponibles dans une seule base de données et tout ce que vous aviez besoin de savoir en tant que spécialiste des données était un peu de R ou de Python pour construire des scripts simples. Pour ma part, je me souviens avoir mis en place un script R, lui avoir fait grignoter quelques données d'une seule table, et lui avoir fait cracher quelques rapports de démarque, le tout intégré dans un tâches CRON solitaire. Mais nous devons tous apprendre une précieuse leçon : les données grandissent.
Au fur et à mesure que les entreprises se développent, de plus en plus de sources de données sont inévitablement ajoutées. Certaines de ces données arrivent par lots et d'autres arrivent par divers canaux : des téraoctets, des pétaoctets de données s'accumulent si rapidement que vous avez l'impression que ça va exploser. Certains d'entre vous l'ont peut-être reconnu il y a des années, lorsque vous avez assumé un nouveau rôle d'ingénieur en données, chargé de stocker les données correctement et en toute sécurité. Si vous vous trouvez dans cette situation délicate, ou si vous commencez à peine à travailler comme ingénieur de données, j'ai de bonnes nouvelles pour vous : Cet article te fournit toutes les ressources dont tu as besoin pour apprendre l'ingénierie des données. Beaucoup de ces ressources sont regroupées dans le parcours de carrière de DataCamp pour les ingénieurs de données.
Le data engineering est essentielle pour les entreprises orientées données, mais que font réellement les data engineers ? L'analogie suivante peut vous aider :
Pensez aux data engineers comme à des cultivateurs, qui s'assurent que leurs champs sont bien entretenus et que le sol et les plantes sont en bonne santé. Ils sont responsables de la culture, de la récolte et de la préparation de leurs cultures pour les autres. Cela comprend l'enlèvement des cultures endommagées pour assurer des récoltes de haute qualité et à haut rendement.
Ce travail est semblable à celui que font les ingénieurs des données pour s'assurer que des données brutes et propres peuvent être utilisées par d'autres personnes dans leur organisation pour prendre des décisions d'affaires fondées sur des données.
Voici les différents savoir-faire à maitriser pour devenir ingénieur data ainsi que des formations en ligne.
- Devenir programmeur
- Apprendre l'automatisation et le scripting
- Comprendre vos bases de données
- Techniques de traitement des données de base
- Planifier vos workflow
- Étudier le cloud computing
- Internaliser l'infrastructure
- Suivre les tendances
1. Devenir programmeur
Avant de nous plonger dans les outils dont vous aurez besoin, vous devez comprendre que les data engineers se trouvent à l'intersection du génie logiciel et de la data science. Si vous voulez devenir un ingénieur des données, vous devrez d'abord devenir un ingénieur en logiciel. Tu devrais donc commencer à rafraîchir tes connaissances de base en programmation.
La norme de l'industrie s'articule principalement autour de deux technologies : Python et Scala.
Apprendre Python
Avec la programmation en Python, il est essentiel que vous sachiez non seulement écrire des scripts en Python, mais aussi que vous compreniez comment créer des logiciels. Un bon logiciel est bien structuré, testé et performant. Cela signifie que vous devez utiliser le bon algorithme pour le travail. Ces cours tracent la voie pour devenir une rockstar de la programmation en Python :
Introduction à Python : Commencez ici si les listes Python ou NumPy ne vous disent rien.
Python intermédiaire pour la data science : Commencez ici si vous ne savez pas comment construire une boucle en Python.
Boîte à outils Python pour la data science (Partie 1) : Commencez ici si vous n'avez jamais écrit une fonction en Python.
Génie logiciel pour les data scientists en Python : Commencez ici si vous n'avez jamais écrit une classe en Python.
Écrire du code Python efficace : Commencez ici si vous n'avez jamais chronométré votre code Python.
Pour approfondir votre connaissance de Python, suivez notre nouvelle piste de compétences sur les meilleures pratiques de codage avec Python. Les connaissances acquises dans ces cours vous donneront une base solide pour écrire du code efficace et testable.
Apprenez les bases de Scala
Dans le monde de l'ingénierie des données, beaucoup d'outils tournent autour de Scala. Scala est construit sur de solides fondations de programmation fonctionnelle et un système de typage statique. Il fonctionne sur la Machine Virtuelle Java (ou JVM), ce qui signifie qu'il est compatible avec les nombreuses bibliothèques Java disponibles dans la communauté open-source. Si cela vous semble intimidant, consultez avec ce cours Introduction à Scala.
2. Apprendre l'automatisation et le scripting
Pourquoi l'automatisation est cruciale pour les ingénieurs de données
Les data engineers doivent comprendre comment automatiser les tâches. De nombreuses tâches que vous devez effectuer sur vos données peuvent être fastidieuses ou doivent se produire fréquemment. Par exemple, vous pourriez vouloir nettoyer une table de votre base de données selon un horaire horaire.
Si vous savez qu'une tâche automatisable prend beaucoup de temps, ou qu'elle doit se produire fréquemment, vous devriez probablement l'automatiser.
Outils essentiels pour l'automatisation
Les scripts Shell sont un moyen de dire à un serveur UNIX ce qu'il doit faire et quand il doit le faire. A partir d'un script shell, vous pouvez démarrer des programmes Python ou exécuter un travail sur un cluster Spark, par exemple.
CRON est un planificateur de tâches basé sur le temps qui a une notation particulière pour marquer quand des tâches spécifiques doivent être exécutées.
Voici un site web génial qui peut vous aider à trouver le bon planning : https://crontab.guru/. Si vous êtes impatient de vous lancer dans le scripting shell et les jobs CRON, commencez par ces cours
Introduction au Shell pour la data science
Traitement des données dans le Shell (la dernière leçon concerne CRON)
Plus tard dans ce billet, nous parlerons d'Apache Airflow, qui est un outil qui repose également sur vos capacités de script pour planifier vos flux d'ingénierie de données.
3. Comprendre vos bases de données
Commencez par apprendre les bases de SQL
SQL est la lingua franca de tout ce qui concerne les données. C'est un langage bien établi et il ne disparaîtra pas de sitôt. Jetez un coup d'oeil au morceau de code SQL suivant :
Ce qui est si beau dans ce code SQL, c'est que c'est un langage déclaratif. Cela signifie que le code décrit ce qu'il faut faire, et non pas comment le faire - le " plan de requête " s'occupe de cette partie. Cela signifie aussi que presque tout le monde peut comprendre le morceau de code que j'ai écrit ici, même sans connaissance préalable du SQL : Retourne combien d'adresses IP distinctes sont utilisées pour toutes les connexions de chaque utilisateur.
Le SQL a plusieurs dialectes. En tant que data engineer, vous n'avez pas nécessairement besoin de les connaître tous, mais il peut être utile d'avoir une certaine familiarité avec PostgreSQL et MySQL. Intro to SQL for Data Science donne une introduction douce sur l'utilisation de PostgreSQL, et Introduction to Relational Databases in SQL va plus en détail.
Apprenez à modéliser les données
En tant que data engineer, vous devez également comprendre comment les données sont modélisées. Les modèles de données définissent comment les entités d'un système interagissent et de quoi elles sont construites.
Vous devriez reconnaître des techniques comme la normalisation de base de données ou un schéma en étoile. Un ingénieur de données sait également que certaines bases de données sont optimisées pour les transactions (OLTP), et d'autres sont meilleures pour l'analyse (OLAP). Ne vous inquiétez pas si ces sujets de modélisation de données ne vous disent rien pour l'instant - ce cours de conception de bases de données les couvre tous en détail.
Apprenez à travailler avec des données moins structurées
Parfois, vous vous trouverez dans une situation où les données ne sont pas représentées de manière structurée, mais sont stockées dans une base de données de documents moins structurée comme MongoDB. Il est certainement utile de savoir comment en extraire les données. Ce cours Introduction à MongoDB en Python peut vous aider dans ce sens.
4. Techniques de traitement des données de base
Jusqu'à présent, je n'ai abordé que les principes de base pour savoir comment programmer et automatiser les tâches, et comment exploiter le SQL. Maintenant il est temps de commencer à construire par dessus ça. Puisque vous avez maintenant une base solide, la limite est le ciel !
Apprenez à traiter des données volumineuses par lots
Tout d'abord, vous devez savoir comment obtenir vos données de plusieurs sources et les traiter : C'est ce qu'on appelle le traitement des données. Si vos jeux de données sont petits, vous pourriez vous en tirer en traitant vos données dans R avec dplyr ou dans Python avec des pandas. Ou vous pouvez laisser votre moteur SQL faire le gros du travail. Mais si vous avez des gigaoctets ou même des téraoctets de données, vous feriez mieux de profiter du traitement parallèle. Les avantages de l'utilisation du traitement parallèle sont doubles : (1) Vous pouvez utiliser plus de puissance de traitement, et (2) vous pouvez également faire un meilleur usage de la mémoire sur toutes les unités de traitement.
Le moteur le plus utilisé pour le traitement parallèle est Apache Spark, qui selon leur site web est un moteur d'analyse unifié pour le traitement de données à grande échelle. Laissez-moi décoder cela pour vous : Spark fournit une API facile à utiliser en utilisant des abstractions communes comme les DataFrames pour effectuer des tâches de traitement parallèle sur des clusters de machines.
Spark parvient à surpasser de manière significative les anciens systèmes de traitement parallèle comme Hadoop. Il est écrit en Scala, et il est utile qu'il s'interface avec plusieurs langages de programmation populaires comme Python et R. Des outils moins connus comme Dask peuvent être utilisés pour résoudre des problèmes similaires. Consultez les cours suivants si vous voulez en savoir plus :
Les bases des grandes données avec PySpark
Introduction à Spark SQL en Python
Le traitement des données se fait souvent par lots, par exemple lorsqu'il y a un nettoyage quotidien programmé du tableau des ventes de la veille. Nous appelons ce traitement par lot parce que le traitement fonctionne sur un ensemble d'observations qui se sont produites dans le passé.
Apprenez comment traiter des données volumineuses en flux
Dans certains cas, vous pouvez avoir un flux continu de données que vous souhaitez traiter immédiatement, ce que l'on appelle le traitement en continu. Un exemple est le filtrage des mentions de stocks spécifiques d'un flux de Tweets. Dans ce cas, vous pouvez vous tourner vers d'autres plateformes de traitement de données comme Apache Kafka ou Apache Flink, qui sont plus axées sur le traitement de flux de données. Apache Spark dispose également d'une extension appelée Spark Streaming pour le traitement des flux de données. Si vous voulez en savoir plus sur le traitement des flux de données avec Kafka ou Flink, consultez cette petite introduction.
Charger le résultat dans une base de données cible
Enfin, avec le travail de traitement des données planifié en place, vous aurez besoin de vider le résultat dans une sorte de base de données. Souvent, la base de données cible après le traitement des données est une base de données MPP. Nous verrons quelques exemples de bases de données MPP dans la prochaine section sur le cloud computing. Il s'agit essentiellement de bases de données qui utilisent un traitement parallèle pour effectuer des requêtes analytiques.
5. Planifiez vos workflows
Ordonnancement du workflow avec Apache Airflow
Une fois que vous avez créé les tâches qui traitent les données dans Spark ou un autre moteur, vous voudrez les programmer régulièrement. Vous pouvez rester simple et utiliser CRON, comme nous l'avons vu précédemment. Chez DataCamp, nous avons choisi d'utiliser Apache Airflow, un outil permettant de planifier les workflows dans un pipeline d'ingénierie de données. Vous devriez utiliser l'outil le mieux adapté à votre workflows. Un simple job CRON pourrait être suffisant pour votre cas d'utilisation. Si les jobs CRON commencent à s'additionner et que certaines tâches dépendent d'autres, alors Apache Airflow pourrait être l'outil qu'il vous faut. Apache Airflow a l'avantage supplémentaire d'être évolutif car il peut fonctionner sur un cluster utilisant Celery ou Kubernetes - mais nous y reviendrons plus tard. Apache Airflow visualise les workflows que vous créez à l'aide de graphiques acycliques dirigés, ou DAGs :*
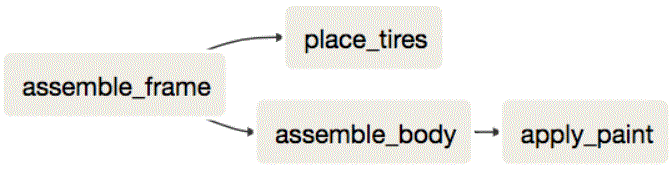
Le DAG ci-dessus montre les étapes de l'assemblage d'une voiture.
Vous pouvez utiliser Airflow pour orchestrer des travaux qui effectuent un traitement parallèle en utilisant Apache Spark ou tout autre outil du grand écosystème de données.
L'écosystème d'outils
En parlant d'outils, il est facile de se perdre dans toute la terminologie et les outils liés à l'ingénierie des données. Je pense que le schéma suivant illustre parfaitement ce point :

Source : https://mattturck.com/data2019/
Ce diagramme est très complet, mais il n'est pas très utile dans notre cas. Au lieu de vous submerger d'un excès d'information, terminons les deux dernières sections avec une illustration qui devrait vous aider à comprendre tous les outils présentés.
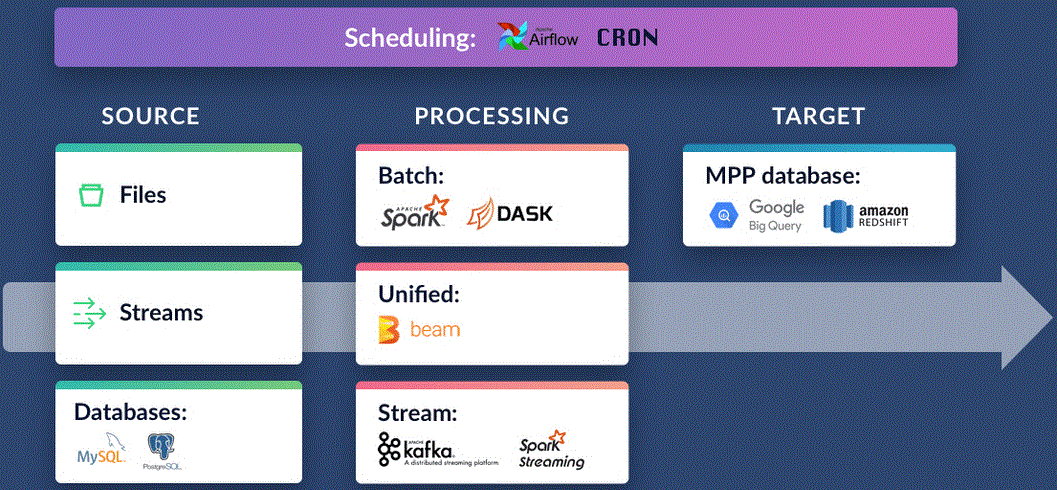
Beaucoup des outils les plus populaires, comme Apache Spark ou Apache Airflow, sont expliqués plus en détail dans ce cours Introduction à l'ingénierie des données.
Un lecteur observateur pourrait voir un modèle émerger dans ces outils open-source. En effet, beaucoup d'entre eux sont maintenus par l'Apache Software Foundation. En fait, beaucoup de projets Apache sont liés à de grosses données, donc vous pourriez vouloir garder un oeil sur eux. La prochaine grande chose pourrait être en route ! Tous leurs projets sont open source, donc si vous connaissez un peu de Python, Scala, ou Java, vous pourriez vouloir jeter un coup d'oeil à leur organisation GitHub.
6. Étudier le cloud computing
Les arguments en faveur de l'utilisation d'une plate-forme de cloud computing
Ensuite, je veux que vous pensiez encore une fois au traitement parallèle. Rappelez-vous que dans la section précédente, nous avons parlé de grappes d'ordinateurs. Dans le passé, les entreprises qui devaient traiter de grosses données avaient leur propre centre de données ou louaient des racks de serveurs dans un centre de données. Cela fonctionnait, et beaucoup d'entreprises continuent à le faire de cette façon si elles traitent des données sensibles, comme les banques, les hôpitaux ou les services publics. L'inconvénient de cette configuration est que beaucoup de temps de serveur est perdu. Voici pourquoi : Disons que vous devez faire des traitements par lots une fois par jour. Votre centre de données doit gérer les pics de puissance de traitement, mais les mêmes serveurs resteraient inactifs le reste du temps.
Ce n'est clairement pas efficace. Et nous n'avons même pas encore parlé de la géo-réplication, où les mêmes données doivent être répliquées dans différents lieux géographiques pour être à l'abri des catastrophes.
L'impossibilité pour chaque entreprise de gérer elle-même ses serveurs est le problème qui a donné naissance aux plateformes de cloud computing, qui centralisent la puissance de traitement. Si un client a du temps libre, un autre peut avoir un moment de pointe, et la plate-forme de cloud computing peut distribuer la puissance de traitement en conséquence. Aujourd'hui, les data engineers doivent savoir comment travailler avec ces plates-formes de cloud computing. Les plates-formes de cloud computing les plus populaires auprès des entreprises sont Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP).
Services communs fournis par les plates-formes de cloud computing
Les plates-formes de cloud computing fournissent toutes sortes de services utiles aux ingénieurs de données. À lui seul, le SSFE offre jusqu'à 165 services. Permettez-moi d'en souligner quelques-uns :
Le stockage en cloud : Le stockage de données constitue la base de l'ingénierie des données. Chaque plate-forme de cloud computing fournit sa version de stockage bon marché. AWS a S3, Microsoft a Azure Storage, et Google a Google Storage. Ils font tous à peu près la même chose : stocker une tonne de fichiers.
Calcul : Chaque plateforme de cloud a aussi son propre service de calcul de bas niveau. Cela signifie qu'ils fournissent une machine distante pour faire des calculs. AWS a EC2, Azure a des machines virtuelles, et Google a son moteur de calcul. Ils sont configurés différemment, mais ils font à peu près la même chose.
Gestion des clusters : Toutes les plateformes de cloud ont leur version d'un environnement de cluster géré. AWS a EMR, Azure héberge HDInsight, et Google a Cloud Dataproc.
Bases de données parallèles : Bases de données à traitement massivement parallèle est un terme fantaisiste pour les bases de données qui fonctionnent sur plusieurs machines et utilisent le traitement parallèle pour faire des requêtes coûteuses. Les exemples les plus courants sont AWS Redshift, Azure SQL Data Warehouse et Google BigQuery.
Traitement des données entièrement géré : Chaque plate-forme de cloud computing dispose de services de traitement des données qui exploitent l'infrastructure/la configuration de DevOps pour vous. Vous n'avez pas à vous soucier du nombre de machines à utiliser dans votre cluster, par exemple. AWS dispose de ce que l'on appelle des Data Pipelines, et il existe également Azure Data Factory et Google Dataflow. Google a ouvert le modèle de programmation de Dataflow dans un autre projet Apache : Apache Beam.
Ce n'est qu'un petit sous-ensemble de services pertinents pour les ingénieurs de données. Si l'un de ces services a éveillé votre intérêt, n'oubliez pas de consulter le premier chapitre de l'Introduction à l'ingénierie des données, qui contient une leçon sur les plates-formes de cloud computing. Si vous souhaitez acquérir plus d'expérience pratique, consultez ce cours Introduction to AWS Boto in Python.
7. Internaliser l'infrastructure
Vous pourriez être surpris de voir cela ici, mais être un ingénieur de données signifie que vous devez également connaître une chose ou deux sur l'infrastructure. Je ne vais pas entrer trop dans les détails sur ce sujet, mais laissez-moi vous parler de deux outils cruciaux : Docker et Kubernetes.
Quand utiliser Docker
La maîtrise de Docker peut vous aider à rendre les applications reproductibles sur n'importe quelle machine, quelles que soient les spécifications de cette machine. C'est un logiciel de conteneurisation qui vous aide à créer un environnement reproductible. Il vous permet de collaborer en équipe et vous assure que toute application que vous faites en développement fonctionnera de la même façon en production. Avec Docker, les data engineers perdent beaucoup moins de temps à mettre en place des environnements locaux. Prenons l'exemple d'Apache Kafka, qui peut être assez écrasant à mettre en place localement. Vous pouvez utiliser une plate-forme appelée Confluent qui package Kafka avec d'autres outils utiles pour le traitement des flux, et la documentation de Confluent fournit un guide facile à suivre sur la façon de commencer à utiliser Docker.
Quand utiliser Kubernetes
Ce qui suit logiquement les conteneurs individuels est un ensemble de conteneurs fonctionnant sur plusieurs machines. C'est ce qu'on appelle l'orchestration de conteneurs dans le jargon des infrastructures, et Kubernetes est l'outil à utiliser. On pourrait à juste titre vous rappeler les traitements parallèles et les outils comme Apache Spark ici. En fait, vous pouvez utiliser un cluster géré par Kubernetes avec Spark. C'est l'un des sujets les plus avancés en ingénierie des données, mais même les débutants devraient en être conscients.
8. Suivre les tendances
Si vous êtes arrivé jusqu'ici, ne vous découragez pas si vous pensez que vous n'avez pas une compréhension complète du paysage de l'ingénierie des données. C'est un vaste domaine qui change constamment. Le plus important est d'utiliser le bon outil pour ce travail et de ne pas trop compliquer les grandes solutions de données que vous construisez.
Cela dit, il n'y a pas de mal à se tenir au courant des derniers développements. Voici une poignée de ressources utiles :
Découvrez les nouveaux logiciels et services comme Delta Lake, Koalas, Metaflow et Rockset.
Regardez les conférences sur ApacheCon.
Gardez un oeil sur les forums comme Hacker News, Reddit et DataCamp.
Regardez les podcasts comme les podcasts The O’Reilly Data Show et Data Engineering.
Ou consultez cette liste d'outils d'ingénierie des données sur GitHub.
Commencez à faire vos premiers pas en tant que data engineer
C'est ça ! Vous êtes au bout du chemin. A ce stade, vous êtes pratiquement un ingénieur de données... Mais vous devez appliquer ce que vous avez appris. Acquérir de l'expérience en tant que data engineer est la partie la plus difficile. Heureusement, tu n'as pas besoin d'être un expert dans tous ces domaines. Vous pourriez vous spécialiser dans une plate-forme de nuage, comme la plate-forme de nuage de Google. Vous pourriez même lancer votre premier projet favori en utilisant l'un des ensembles de données publics BigQuery de Google.
